








活动专题

时间:2023-08-18 09:49:01 来源:公安部鉴定中心、济南市公安局
[内容导读] 近年来,自动人脸识别技术广泛地应用于刑事侦查。然而在法庭科学领域,不同厂商算法模型的人脸比对分数差异较大,需要量值校准才能实现


近年来,自动人脸识别技术广泛地应用于刑事侦查。然而在法庭科学领域,不同厂商算法模型的人脸比对分数差异较大,需要量值校准才能实现可比较、可追溯的检验,在诉讼证据层面评估和解释人脸图像相似度分数依然是一个挑战性的课题。根据案件中人脸图像比对的应用场景,我们收集了200000个对象的监控截图及证件照片,测试数据集中还混入亿级干扰样本。本文报道了国内厂商14个最新算法基于上述数据集的测试结果。使用整体表现、正负样本分数分布、似然率曲线来评估不同算法的可用性、可靠性和证据价值。本文还讨论了似然比极限及基于D-S证据理论的多个人脸识别算法在分数层的融合问题。
一、引言
特征比对方法是各个科学领域研究的重要方法,更是法庭科学的核心方法。特征比对方法的每一步发展,都会有力的推动法庭科学的进步,而其有效性及可靠性问题也极大的影响法庭证据的应用。鉴于此,国际上都非常重视特征比对方法。
法庭科学中的特征比对方法可分为客观方法和主观方法。目前,法庭科学中大部分物证特征比对方法属于主观方法。基于客观方法的比对鉴定受到物证特征条件及数据支撑的限制,法庭科学特征比对客观方法一版采用小样本测试方法估计正负样本相似度分数的分布,再技计算似然比。
与其他生物特征相比,人脸图像的获取是非侵入性的、无需被采集者配合,近年来,公安视频监控系统大量建设,视频采集的清晰度日益提高,人脸图像开始成为案件中最为常见的物证。近年来,随着基于深度卷积神经网络的人脸识别技术的发展,人脸比对的准确率取得了较大的突破,人脸图像客观方法鉴定展现了巨大的应用潜力。
二、人脸图像相似度分数的证据应用现状
在人脸特征比对方面,主观方法开展较早。国内外均形成了相关的技术方法和行业标准。然而,学术界中不乏质疑之声:2007年,Kleinberg等人对人脸鉴定中特征的可靠性提出疑问;而McNeill Allan等人认为“这些(研究)结论暗示,在法庭上持续接受人脸比对证据,更倾向于增加而不是减少错误定罪的发生”。
人脸特征比对客观方法方面,J. Gonzalez探讨了贝叶斯方法在指纹、人脸和签名证据中的应用,利用早期的人脸识别系统进行人像特征比对,使用了基于特征脸空间和线性判别分析(Linear Discriminant Analysis)相结合的人脸识别方法和基于分数的似然比计算方法,特征之间的分数为归一化标量积,支撑似然比的统计数据正样本照片数为400对,负样本照片对数为152000。Allen. R对人脸鉴定中的贝叶斯理论应用进行分析,采用的特征是比例指数。T. Ali 等人讨论了嫌疑锚定和嫌疑独立两种数据库情下,人脸识别系统分数似然比的差别,实验使用的人脸识别系统基于的人脸特征未知。Domingo等人讨论了不同人脸识别系统计算似然比的可复现性和重复性,采用基于离散余弦变换(DCT)系数特征。其统计的正样本最大数目为400对,负样本最大数目为40000对。这些研究结果支持了人脸特征比对客观方法的可行性,但是存在的主要局限一是实验数据量有限,二是受当时的条件所限,并未使用基于深度学习提取特征的人脸识别系统。因此,人脸特征比对的客观方法,并未受到过多的重视,也未得到有效的应用。
目前在国内的实际应用中,人脸特征比对仍主要采用主观方法,但较多国内外学者认为,基于统计框架的特征比对客观方法,是当前法庭科学发展的方向。
三、 基于刑侦大数据的人脸识别算法测试
(一)数据集
一般地,根据应用场景自行采集的各类人脸数据集,如图1所示,根据涉及的人物身份对人脸数据集进行整理,建立人物身份ID(N个人物)和图像ID(其中M人至少有2张人脸图像,M≤N)之间1对多的对照表(A),将测试数据分样本图像组(N张图像,每人抽取1张质量最优的图像作为样本)和检材图像组。
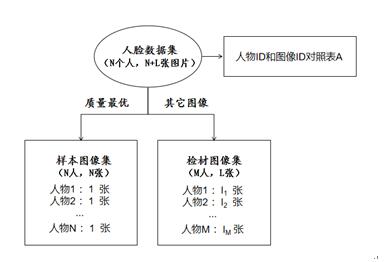
图1 准备测试数据集的流程图
在目前的测试中,我们通过上述步骤已收集了200000个对象的检材图像和样本图像(每人监控截图和证件照片各1张),及7500万个对象的干扰样本图像(每人只有证件图像1张)。数据集中监控截图质量满足 GA/T 922.2-2011 [38]的要求,证件照片质量满足GA 461-2004 [39]的要求。
(二)算法测试
为测试人脸比对算法的有效性,美国国家标准与技术研究院定期会基于大规模数据对各厂商提交的1:1人脸比对算法进行测试(FRVT),通过人脸比对算法分别提取人脸图像的特征,计算特征距离并映射到0至1的范围,通过划定阈值得到肯定性或无法确定的结论,主要指标有首位识别准确率、指定错误接受率下的错误拒绝率、注册失败率等。该评测方法有三方面问题:一是在多算法评测中,随着算法训练中实战数据的增多,算法精度均有显著提升,首位识别率指标差别较小,难以区分算法优劣。二是在非全量人口数据集上,首位识别不能等同于特征相似度指标在身份认定上是有效的,方法无法获得同一人和不同人人脸图像特征比对相似度的概率分布。三是缺少法庭科学应用中最核心的对身份认定结果准确性的评测指标。
面对法庭科学嫌疑人身份认定场景,算法的评测应可以通过测试正样本(同一人的两张人脸图像)、负样本(不同人的两张人脸图像)的相似度数值,得到算法相似度分数的随机抽样分布。经过大规模数据随机抽取测试,可得到误差极小的算法相似度概率分布。正、负样本概率分布作为算法评测的核心指标,具有良好的区分度,可避免测试数据重复使用导致的简单准确率、首位识别率指标失效等问题。
测试中,可以调用各算法厂商已集成的人脸识别系统的入库、1:N比对接口,快速获得大规模数据的正、负样本相似度分数概率分布这一核心指标,完成对系统应用的人脸图像比对算法模型的有效性、可靠性、鲁棒性评价。因此,这种评测方法适用于法庭科学嫌疑人身份认定场景下对于人脸比对算法证据转化能力的评价。
使用待测试的人脸比对算法对所有样本图像组提取特征,建立样本人像特征库,入库特征n组,计算样本入库成功率指标 。
抽取1张检材图像,如图2所示,使用待测试的人脸比对算法提取人脸图像特征,如提取失败,则更新失败日志;如提取成功,则与样本人像特征库进行逐一比对计算相似度,新建以图像ID命名的csv格式的结果文档,依次写入n条样本图像ID和相似度数值S,相似度数值 均在0至1之间取值。重复图2步骤,直至遍历所有检材图像组图像,得到结果文档 份,计算检材特征提取成功率指标 。
依次读取所有结果文档中所有比对数据( 条),根据对照表判别比对数据属于正样本相似度或付样本相似度,累计正样本相似度统计量和负样本相似度统计量。
法庭科学场景下,根据检材和样本人脸图像判定身份是否一致,涉及肯定判决和否定判决的阈值。以错误接受率(FAR)为亿分之一为标准选定肯定判决阈值,计算肯定判决准确率指标 。以错误接受率(FRR)为亿分之一为标准选定否定判决阈值,计算否定判决准确率指标 。
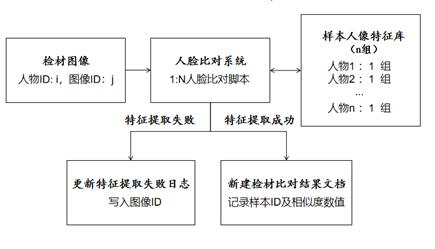
图2 获得正、负样本分布似度概率分布的流程图
(三)算法效能
评价算法效能涉及两项测试:测试一,10万个对象,监控截图和证件照片每人各1张,分别组成检材样本集和测试样本集;测试2,10万个对象,监控截图和证件照片每人各1张,分别组成检材图像集和样本图像集,样本图像集中加入7500万张干扰对象的证件照片。整体表现指标有:
测试一、测试二分别计算的正、负样本相似度概率分布曲线如下图3所示。
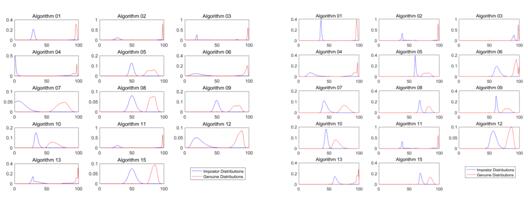
测试一 (b)测试二
图3 正、负样本相似度概率分布曲线
四、人脸图像相似度分数的证据应用
(一)似然比计算
人脸特征比对采用似然比框架,有许多方法。如[35]使用人脸特征(具体为比例指数),通过对(比例指数)特征的统计数据估计其分布参数,从而计算似然比。这种对人脸特征的概率统计方法比较直观。但是要想得到较精确的分布,需要大量数据,而大量数据下的特征提取工作又难以稳定的进行,具体实施较为困难,因此在人脸特征比对中采用这种方式的研究并不是太多。但是在DNA物证检验中是经典的似然比模式。
在人像比对检验中,检验的对象是嫌疑人的人脸图像(已知对象,样本X)和作案人的人脸图像(未知对象,检材Y)。人脸比对系统提取人脸图像的一组特征,特征通常为一组高维向量,对于可获取的作案人和嫌疑人的人脸图像分别进行特征提取,可将分别提取到的特征作为对X和Y的一种生物计量值,分别表示为x和y。由于客观方法提取的人脸图像特征是连续的检验值。
主流的方法都开始改变直接对特征比对进行统计的思路,采取对人脸特征比对的某种函数进行分析,将多个特征比对转化为一个特定的函数值,称之为基于分数的似然比方法。这种分析方法较早在语音中使用,也在其他的物证中广泛采用,如书写材料、指纹和签名等。一般地说,似然比计算模型如下图4所示。
基于分数的似然比计算的基本结构如下:
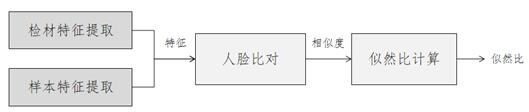
图4 分数似然比计算框架
在人脸比对检验中,存在两种对立假设:
控方假设, H_0支持犯罪现场收集到的人脸图像来自某一嫌疑人。
辩方假设, H_1支持犯罪现场收集到的人脸图像来自其他人。
在客观方法中,人脸比对算法计算的相似度分数S可以作为观察到的证据E,根据贝叶斯公式,后验概率可以表示为:
(P(H_0 |E))/(P(H_1 |E))=(P(H_0))/(P(H_1))×(P(E|H_0))/(P(E|H_1)) (1)
基于大规模、标签准确的人脸图像数据集,归纳和拟合人脸图像特征相似度分布规律,进行基于分数的人脸图像似然比计算方法研究,实现人脸比对相似度的证据转化。似然比(LR)是P(E│H_0 ) 和P(E│H_1 )之比,对应着证据的强度。基于统计数据,我们可以通过下式计算似然比。
LR(S)=(P(S|H_0))/(P(S|H_1)) (2)
连续的相似度分布可以进行离散化,N_g 和 N_i 分别代表正、负样本对总数量. N_g^s 和N_i^s 分别代表下相似度分数离散化后取值为 S的正、负样本对数量. P(S│H_0 ) 和 P(S│H_0 ) 可以通过下两式近似计算:
P(S|H_0)=lim┬(N_g→∞)〖(N_g^s)/N_g 〗(3)
(二)似然比解释
人脸图像的似然比指的是“假设检材人脸图像与样本人脸图像源于同一人的条件下得到相似度系数的可能性与假设二者不是源于同一人的条件下得到相似度系数的可能性之比”。当似然比大于等于10000000时,我们在机器可区分范围,检材人脸图像与样本人脸图像的特征相同。当似然比小于1时,认为检材人脸图像与样本人脸图像的特征不同。检验结果中的“特征”特指人脸图像特征。“特征相同”的含义为所使用的检验系统已经无法区分特征之间的差别。
在假设实际案件中正、负样本相似度分布与测试中相同的条件下,人脸图像存在如下分布概率:对于任意检材人脸图像,在与随机人群人脸图像进行比对的情况下,似然比达到一千万的概率不高于一亿分之一,即检材图像与随机人群人脸图像特征相同的概率不高于一亿分之一。
一些双胞胎的人脸图像之间的似然率能够达到一千万以上。
一些特定情况下,如同一人整容前后的人脸照片之间、同一人年龄相差较大的人脸图像之间的似然率存在小于1的情况。
(四)似然比极限
在14种算法的测试中,虽然算法的相似度分布曲线各不相同,但其似然比极限却都在8-9之间,如图5所示。这一数字在2013年相关文献的报道中是3-4,可以看到人脸识别技术的进步对于证据价值评估的巨大影响。
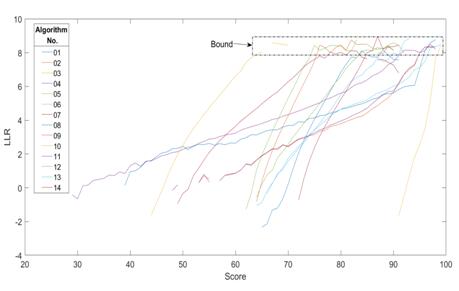
图5 测试一种算法似然比的极限
责任编辑:广汉
声明:
凡文章来源标注为"智领安平行业网"的文章版权均为本站所有,如需转载请务必注明出处为"智领安平行业网",违反者本网将追究相关法律责任。非本网作品均来自互联网并标明了来源,如出现侵权行为,请立即与我们联系,待核实后,我们将立即删除,并向您致歉。



.jpg)
.jpg)






 京公网安备 11010602007722号
京公网安备 11010602007722号