


活动专题

时间:2023-10-12 13:52:18 来源:张光君 张翔 蒋佳 丁钰 谭俊 姚尚吾
[内容导读] 【摘 要】法律发现智能化是类脑智能推理的关键环节,通过智能检索精准呈现类案,则是法律发现智能化的基本前提。现行类案检索系统处理


【摘 要】法律发现智能化是类脑智能推理的关键环节,通过智能检索精准呈现类案,则是法律发现智能化的基本前提。现行类案检索系统处理端依据案由进行案例类型化和字符串匹配后获取的“类案”,与输入端待决案件关键词目标语义所期待的类案相距甚远。法律发现的本质是抽象规范的定型化,这需要以深度学习技术精准识别类案、建构类案同判规则数据库,在此基础上,通过NMT架构下综合应用无监督学习训练方式来提升抽象规范定型的精准度,从而助推法律发现智能化转型。
【关键词】类案检索;抽象规范定型化;法律发现;智能司法
一、引言
为进一步落实习近平总书记关于推进智能司法、统一法律适用的一系列重要指示,最高人民法院积极探索“基于案件事实、争议焦点、法律适用类脑智能推理”,以“满足办案人员对法律、案例、专业知识的精准化需求。”类脑智能属于高技术水平的认知仿生驱动,法律适用类脑智能推理将是智能司法“质的飞跃”。然而,当前智能司法尚处于以模型学习驱动的数据智能阶段,现行类案检索系统因欠缺精准性而沦为“鸡肋”,无法为法律发现智能化奠定坚实基础,进而阻滞智能司法“质的飞跃”。因此,当务之急是激发案例大数据的潜能,通过底层思维范式转变,以类案智能检索助推法律发现智能化转型。
二、类案检索不精准及形成原因
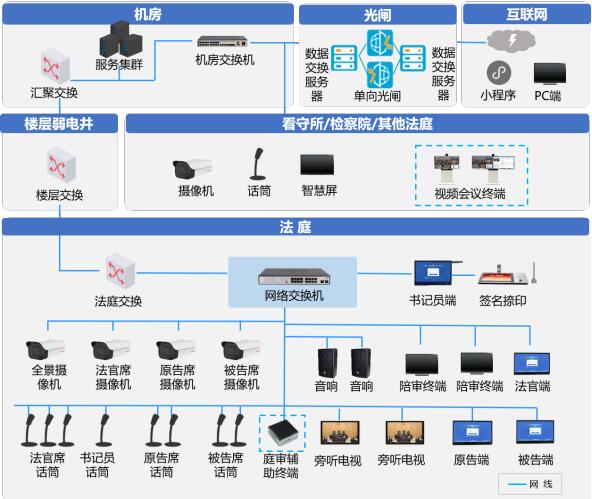
类案检索不精准主要表现为检索不到类案的“隐性缺失”(事实上有类案)和检索到表面关联案件的“显性缺位”(貌合神离)。也即,现阶段只是筛选了形式上法条援引相同、实质上事实不同的案件进行比对,以至于形式上关联案件数量庞大而实质上多为高频词汇简单重叠。从现行类案检索系统的运行原理(如图1所示)看,输入端往往采用关键词检索确定目标语义,处理端则通常依据案由对案例数据类型化后,再拆解该类裁判文书语词并进行数据标注,通过目标语义与案例数据库比对,依据关键词重合度及复现频次高低筛选类案。事实上,案由是立案、分案等审判管理工作的标准,其内在逻辑与法官依据争议焦点提炼的法律关系并不完全一致,加上数据处理只是语词之间机械性的字符串匹配,虽然比对结果具有概率论意义上的高度相关性,但却与目标语义下潜藏的法律关系的结构性关联相距甚远。譬如,当前中国裁判文书网中民事案件数量总计8千余,在种类最丰富的473个三级民事案由中,平均每个案由下就有裁判文书17.2万篇,但实践中相同案由的案情错综复杂,以此种检索方式试图在17.2万篇相同案由的案例中精准定位与待决案件高度相似的类案,无异于大海捞针。究其原因,人工数据标注无法穷尽各类语境中语词的真实语义,而数据结构化也并非建立在知识图谱基础上,使得当下的数据标注只能实现低层次的数据结构化,搜索技术因知识图谱缺失也必然会减损语词之间可能的深层语义关联。
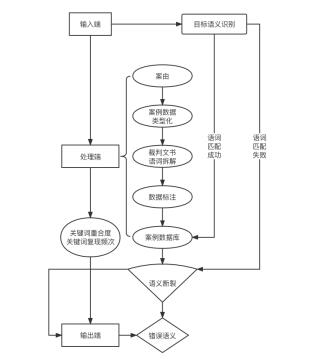
图1:现行类案检索系统的运行原理
三、法律发现原理及智能化需求
待决案件事实依据其类型能否被纳入法律概念的评价范畴之中,该判断过程并非法官“直觉式的跳跃”,而是解决法律规范之含义精确化的问题。涵摄思维无法回答特定事实究竟是怎样被归入法定要件的语义射程范围内,需要从诠释学意义上对法律规范(涵摄的大前提)通过“类型化的案例比较”加以衡量,也即通过“抽象规范定型化”精准锁定规范语义(如图2所示)。
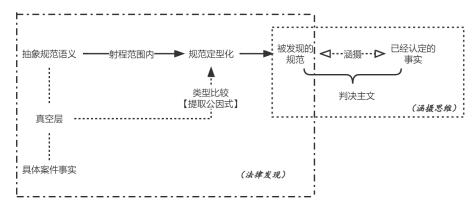
图2:法律发现与涵摄思维的区别
在英美法系的遵循先例原则之下,需要经过“类型化的案例比较”,以识别将待决案件和先例置于同一法律规范之下需要具备的共同要素,或区分待决案件不具备先例据以成立的关键要素。一旦区分成功,则待决案件与先例的差异性足以使该案必须作出与先例不同的判决。在大陆法系,通过规范与事实之间往返流转,将待决案件归入或不归入某一规范的适用范围,不断特定化法律概念的意义范畴。由此从规范的核心含义以及属于该核心含义的案例类型出发,进一步划定规范意义范围的边界。其中,归入性判断的关键便是“比较”,一方面需要确定被比较的案例类型之间的一致性要素,另一方面也要确定它们之间的差异性要素,并秉持实质标准进行权衡,最终基于“合目的性”约束选择最为适切的法律解释(如图3所示)。
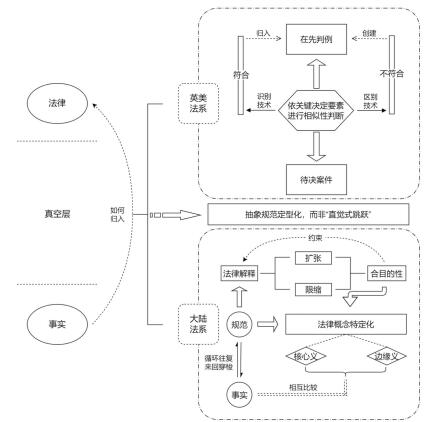
图3:法律发现的基本原理
两大法系法律发现的基本原理揭示出,法律发现的本质就是抽象规范定型化,该定型化过程也是解决归入难题的“牛鼻子”。但是,依靠直接的审判经验积累或者间接的法教义学分析能力提升,显然既不能回应“案多人少”之矛盾,也无力穷尽所有审判经验以最大化地形成知识增量。因此需要借助大数据、人工智能技术优化类案检索系统,以便全面、准确地挖掘出案例数据之间多维度的深层次关联,进一步以识别出的、与待决案件高度关联的类案为基础建构“类案同判规则数据库”,从而形成抽象规范定型化的数据基础。事实上,案例语词的细节化程度与定型化规范语词的抽象度呈负相关,而裁判文书作为原始数据,其语词整体上抽象化程度低、细节化程度高,这就需要对大量非线性结构的裁判文书进行信息抽取、知识融合与知识加工,而深度学习能够模拟人脑的分层结构,将外部输入的数据自动从低级到高级进行特征提取,从而实现对外部数据更为精准的解释,避免传统机器学习中的人工特征选择(如数据标注)等步骤,减少并改善特征抽取过程中的误差积累问题。(如图4所示)
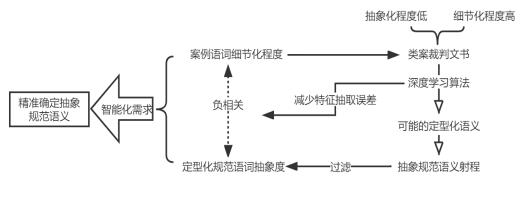
图4:法律发现的智能化需求
四、法律发现智能化的实现路径
类案检索智能化是法律发现智能化的前提。类案智能检索首先需要利用无监督学习进行类案事实提取,充盈类案同判规则数据库;第二,依据法律规范构成要件要素将待决案件拆分后,整体置入类案同判规则数据库;第三,通过基于深度学习的知识图谱进行事实关系匹配,将无维度标签的数据进行聚类整合以实现类别归纳。较之于关键词检索遍历结点固定顺序的“盲目搜索”策略,基于深度学习构建知识图谱后,可以通过非线性检索方式,避免案由具化检索有限性带来的检索结果隐性缺失,还可以在案例之间建构“去中心化”的深度关联从而避免检索结果的显性错位。减少了对外部工具和人工特征选择的依赖,可以有效完成端到端的实体识别、关系抽取和关系补全等任务,实现知识图谱的自动构建与内外协调,进而使类案得以精准呈现。
无论是传统类案识别所用的知识图谱,还是试图提升类案判断准确度的事理图谱,在法律文本或类案的语义分析时均以NLP(Natural Language Processing,自然语言处理)为基础,都难以摆脱语词歧义等困境。而建基于NMT(Neural Machine Translation,神经网络机器翻译)的抽象语义框架,则可通过训练模型自动注释数百万个未标记的语句,在生成相关内容时更加关注上下文来解析句法和语义。无监督学习在多维度拓展类案相关关系后,进一步在NMT框架下运行将会更加精准地进行语义关联,更加契合抽象规范定型化对规范语言多义性识别的建模需求,进而助推法律发现的智能化转型(见图5)。
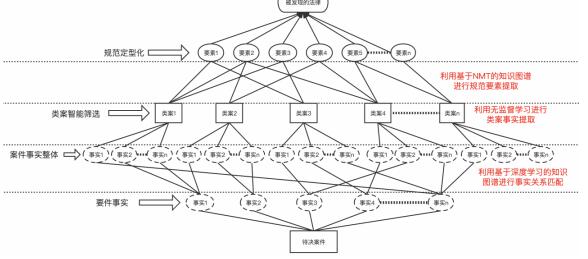
图5:法律发现智能化的原理与过程
五、结语
更新底层思维并通过深度学习技术提升类案检索精准度之后,综合应用无监督学习等深度学习技术,继续促进NLP向NMT架构优化,进而实现法律发现的智能化转型,由此打通了类脑智能推理的关键环节。当然,法律适用类脑智能推理还离不开事实认定以及涵摄过程的智能化,仍需区块链技术赋能。在习近平法治思想的指引下,随着大数据、人工智能、区块链等新一代信息技术与司法工作持续深度融合,必将持续推动人民法院审判质效的数智化升级。
责任编辑:广汉
声明:
凡文章来源标注为"智领安平行业网"的文章版权均为本站所有,如需转载请务必注明出处为"智领安平行业网",违反者本网将追究相关法律责任。非本网作品均来自互联网并标明了来源,如出现侵权行为,请立即与我们联系,待核实后,我们将立即删除,并向您致歉。

您可能感兴趣的文章




.jpg)
.jpg)






 京公网安备 11010602007722号
京公网安备 11010602007722号